本文将介绍一些 Spring Data JPA 使用过程中容易出错或者需要注意的一些点的最佳实践方案;并会提供对 Spring Data JPA 核心部分源码分析并自己实现一个MyJPA(附源码);

0x00 简介
本文将介绍一些 Spring Data JPA 使用过程中容易出错或者需要注意的一些点的最佳实践方案;
并会提供对 Spring Data JPA 核心部分源码分析并自己实现一个MyJPA(附源码);
分享会录屏:https://vimeo.com/661399278 密码1321
0x01 最佳实践
本人工作这些年也是80%使用 CodeFirst 这种仓储技术框架,而非 DBFirst 的 Mybatis 等;所以从以往工作的经验中总结出来一些个人认为的最佳实践方式,如有不妥可以提出意见,并且哪些点适合应用到咱们项目可以一起讨论;
LogicDelete
逻辑删除在我们工作中很常见,但是往往使用方式都是机械化的;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29//逻辑删除重复代码太多,每个实体都需要这样的方法,能否封装一下?
public void deletePaymentPlan(Long id) {
PaymentPlan paymentPlan = getPaymentPlanEntity(id);
paymentPlan.setDeleted(true);
paymentPlanRepository.save(paymentPlan);
}
```
方式1:并不推荐,不够灵活,还需要人工对每个 Entity 写sql,万一字段变动怎么办?如果我需要物理删除又怎么办?
```java
//通过注解直接替换调用delete时的真实物理删除逻辑
(sql = "UPDATE t_user SET deleted = true WHERE id=?")
(name = "t_user")
public class User {
private Long id;
private String name;
private boolean deleted = false;
}
void sqlDelete() {
final Optional<User> byId = userRepository.findById(1L);
userRepository.delete(byId.get());
}
方式2:最佳实践?感觉也不是很优雅,那我要物理删除怎么办?其实这个问题跟下一个聊的相关,到时候一起解答。我们带着问题往下看1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//jpa都是接口默认都是 SimpleJpaRepository 实现类,通过替换实现类并重写delete方法
(repositoryBaseClass = CustomerBaseRepository.class)
public void JPAConfig{xxx}
public class CustomerBaseRepository<T extends AuditModel, ID> extends SimpleJpaRepository<T, ID> {
public CustomerBaseRepository(constructor fill parent param);
//override delete(T entity)
public void delete(T entity) {
entity.setDeleted(true);
em.merge(entity);
}
}
BaseRepository
目前的每一个 Repository 都会继承2个 JPA 相关的接口,赋予相应的能力,JpaRepository基础CURD能力,JpaSpecificationExecutora 提供Specification查询能力;
但是每个仓储都需要实现这两个接口会不会太麻烦了,我后面需要再添加一种其他能力怎办?到处去改?1
2
3
4
public interface InvoiceRepository extends JpaRepository<Invoice, Long>, JpaSpecificationExecutor<Invoice> {
}
最佳实践(LogicDelete + BaseRepository)
抽象一个 BaseRepository 所有仓储接口都继承自它,方便扩展;
逻辑删除通过 SpEL 表达式的方式通用并定义在 BaseRepository 中,让所有实现类都扩展此能力;
1 |
|
Entity Status
我们先来看一张图,这是 JPA 实体的四种状态,我们核心关注 Persistenent 持久化状态,如果一个对象被保存或者从数据库中 get 出来,那么他都是持久化状态。
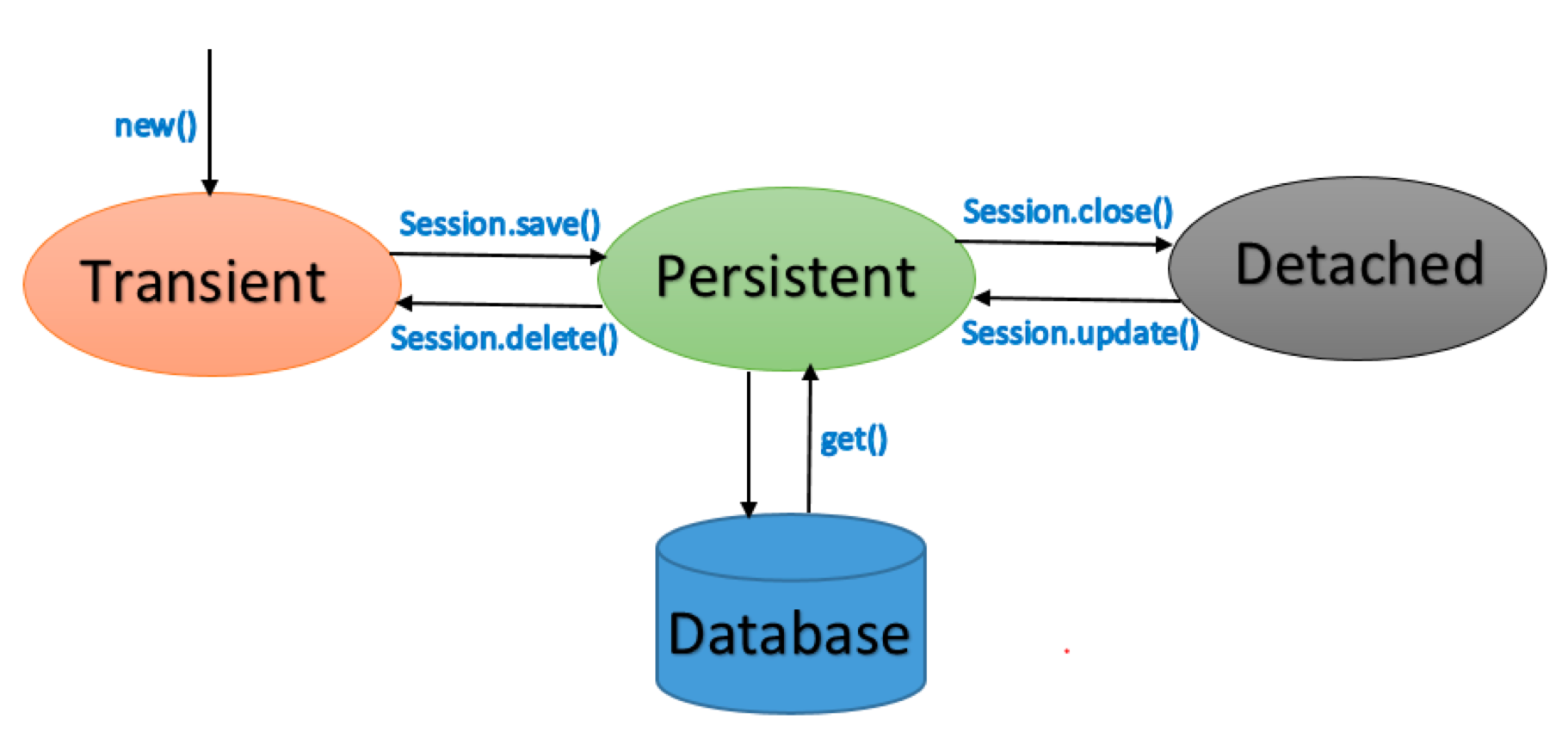
我们现在有一个核心的点需要关注,hibernate 如果是持久化状态的对象,在事务结束 flush() 的时候都会判断每一个持久化对象的字段 isDirty(),true表示这个字段有变化,会自动帮你储存到数据库中。
最佳实践
所以这也是为什么我们业务开发过程中只要修改了实体的属性,就算不调用 save 方法也会被更新到数据库中,这在开发中往往很容易误解开发人员,所以建议只要有更新操作都要显式的调用 save 方法;
1 |
|
Relationship Mapping
多表之间的关联关系使用起来让我们很放便,但是也有很多需要注意的坑;
1 | /** |
如果我们忘了在 OneToOne 被关联的一侧忘记添加 mapperBy,则会在主表 user中也生成一个 user_address_id 字段;
1 | /** |
最佳实践
单向关联(只有一方需要维护关系)
只需要在有拥有外键的一方添加注解@JoinColumn,并指定增加的id字段
双向关联(双方都需要维护关系)
被关联方加上注解并且加 mappedBy
Lazy Load
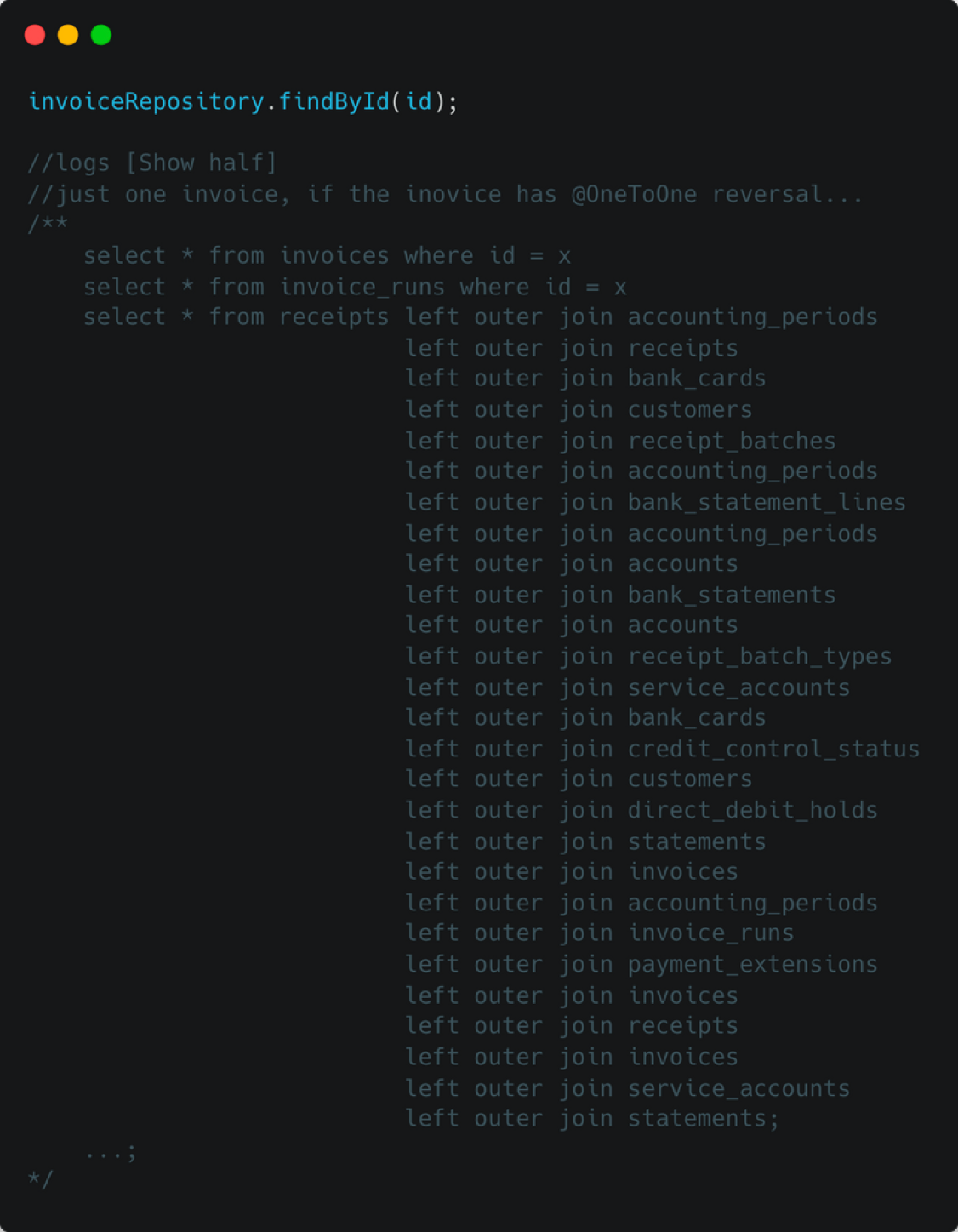
我们先来看一个稍大对象的根据id查询的时候执行的sql日志;这仅仅展示了一半,若这个 invoice对象对应的一对一的 reversal 对象油值的话,那么将会是双倍的sql日志;
下面是我们关联关系注解中默认的加载机制,我们可以发现只有 OneToMany和ManyToMany是默认懒加载的
1 | FetchType fetch() default EAGER; |
最佳实践
非特殊情况请将 FetchType设置为 LAZY
SQL N+1
什么是 JPA 的 N+1 问题?我们可以看到以下例子,我们 user 表有3条记录,对应的每个用户有2个地址记录,findAll(), 需要执行4次查询。 理想情况中我们是希望查询关联表的信息可以通过 left join 或者 in 来通过一句 SQL 就完成的;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class User {
(mapperBy="user", fetch=FetchType.EAGER)
private List<Address> addresses;
}
public class Address {
(name = "user_id")
private User user;
}
public void test() {
userRepository.findAll();
}
//user 3 records, every user has 2 address;
//select * from user;
//select * from address where user_id = 1;
//select * from address where user_id = 2;
//select * from address where user_id = 3;
最佳实践
方式一:若需要全局配置的情况请使用 default_batch_fetch_size 默认是 -1,代表不会批量查询
方式二:@BatchSize同等于方式一,但是灵活支持对象上使用;
方式三:@Fetch(value = FetchMode.JOIN) 局限只支持 id 或者 联合主键;
方式四:不推荐,人工来做多表关联查询设置属性值;
1 | //way1: the default is -1, never batch fetch, every query get max 20 |
CascadeType
CascadeType支持 ALL、PERSIST、MERGE、REMOVE、REFRESH、DETACH。我们应该使用他们吗?1
2
3(cascade = CascadeType.ALL)
(name = "receipt_id")
private Receipt receipt;
最佳实践
并不推荐使用 CascadeType,因为它违背了单一职责(ddd的项目中值对象可能有这样的用法),并且非常难以控制特别容易误删除之类的操作;最好还是业务逻辑来维护它对应仓储的能力;
Foreign key constraints
外键约束该不该使用?什么情况下适合使用?1
2
3
(name = "receipt_batch_type_id", foreignKey = (ConstraintMode.NO_CONSTRAINT))
private ReceiptBatchType receiptBatchType;
最佳实践
使用外键约束
优点:适用于非集群系统,数据库层面做约束校验
缺点:会稍微降低一点性能、不容易扩容或者分表分库等
禁用外键约束
优点:适合分布式、高并发集群,性能稍高
缺点:业务来维护数据约束关系
Specification
先来看一个我之前写的Specification语法的查询,仅仅是一个很简单的查询,一是写起来太痛苦了,二是一大块代码一点都不优雅很难看,如果查询条件一多可想而知;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public Page<PaymentPlanDTO> getPaymentPlans(PaymentPlanQuery paymentPlanQuery) {
final Long serviceAccountNumber = paymentPlanQuery.getServiceAccountNumber();
return paymentPlanRepository.findAll((root, criteriaQuery, criteriaBuilder) -> {
final List<Predicate> predicates = new ArrayList<>();
if (serviceAccountNumber != null) {
predicates.add(
criteriaBuilder.and(
criteriaBuilder.equal(root.get("serviceAccountNumber"), serviceAccountNumber)
)
);
}
predicates.add(
criteriaBuilder.and(
criteriaBuilder.equal(root.get("deleted"), false)
)
);
return criteriaBuilder.and(predicates.toArray(new Predicate[0]));
}).map(MAPPER::toDTO);
}
最佳实践
封装 Specification 处理逻辑;我们来对他进行封装一下(封装方式多种我这个并不一定是最优解);
1 |
|
怎么使用?1
2
3final CustomSpecification<Offering> nameCriteria = new CustomSpecification<>(new SearchCriteria("code", SearchCriteria.Operator.EQ, "test"));
final CustomSpecification<Offering> descriptionCriteria = new CustomSpecification<>(new SearchCriteria("description", SearchCriteria.Operator.EQ, "tester222"));
offeringRepository.findAll(Specification.where(nameCriteria).and(descriptionCriteria));
EntityManager
JPA的EntityManager是一个核心的方法,所有JPA方法都是基于他封装的,而可能有些时候我们需要这个对象来做一些事情,那么怎么注入它?1
2
3
4
5
6
7//bad
private EntityManager entityManager;
//good
private EntityManager entityManager;
最佳实践
请使用@PersistenceContext来注入它;它不是线程安全的,如果使用Spring的方式注入默认都是单例的,SpringMVC每一个请求都是单独的一个线程,会造成线程安全问题;
They are also used when directly injecting EntityManager instances can’t be done because EntityManager instances are not thread-safe.
https://docs.oracle.com/cd/E19798-01/821-1841/bnbqy/index.html
Optimistic locking
乐观锁我们都知道,@Version 配合一个数值类型的属性嘛很简单。但是仅仅这样就可以了吗?
使用乐观锁代表可能会出现冲突,出现冲突就直接报错?那用户体验也太差了吧;
最佳实践
乐观锁请配合@Retry重试功能来使用,重试仅仅针对乐观锁的报错!!!并且重试是随机时间,避免引起重试风暴(同时重试压力大、重试并发高乐观锁又会获取失败);
阿里开发规范:如果每次访问冲突概率小于 20%,推荐使用乐观锁,否则使用悲观锁。乐观锁的重试次数不得小于3次。
1 |
|
@DynamicUpdate / @DynamicInsert
使用了这个注解非空的字段不会进行update和insert1
2
3
4
5
6
7
8
9
10
11
public class User() {}
//insert into t_user set name = 'kok',code=..other fields.. where id = 1;
//insert into t_user set name = 'kok' where id = 1;
public void test() {
User user = userRepository.findById(1L);
user.setName("kok");
userRepository.save(user);
}
最佳实践
非空字段不进行update和insert。提高sql执行效率,不仅仅是减小非空字段的插入的效率,而是update全部更新往往会导致一些索引字段也进行更新;需要维护BTree索引;
但是会增加hibernate的开销,需要去判断哪些字段是有更新的
所以建议一般带有fat blob情况下才使用;
@Transaction
这个注解大家都会用,但是怎么用才是最合适的呢,比如在整个class上设置了@Transactional,那么这个类所有的方法都会具有事务能力。万一在某个读取的方法中不小心调用了一个需要写的方法或者把一个entity的属性改变了,那么就会自动更新到数据库(Entity Status那一节讲的持久化状态);
1 |
|
最佳实践
类上面指定 @Transactional(readOnly = true) 代表所有方法都是只读;
仅仅在需要事务操作的方法上面制定 @Transactional 来开启事务。让事务可控;
1 |
|
Transaction failure
我们都知道在开发中不小心的话很容易遇到事务失效的问题,下面举一个常见的例子,自己调用自己(因为事务需要动态代理包装,就算A被事务包装了,但是通过 this 自己调用自己内部的方法不会生效,没有调用到被Spring增强的事物方法);
1 | /** |
最佳实践
通过在 JDBC URL中添加 MySQL提供的参数;(PG貌似没有,一直在找)
logger=com.mysql.jdbc.log.Slf4JLogger&profileSQL=true
https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-configuration-properties.html
1 | //only for mysql |
Spring Data JPA Test
JPA相关的单测我们如何写,如果是 @SpringBootTest 就太臃肿了,会启动整个 application context;
最佳实践
@SpringBootTest loads full application context, exactly like how you start a Spring container when you run your Spring Boot application.
@DataJpaTest loads only configuration for JPA. It uses an embedded in-memory h2 if not specified otherwise.
@DataJpaTest 仅仅会启动JPA相关的配置,而且会用默认内置的 h2 内存数据库,速度极快,需要引入对应的依赖。当然你换成PG、MySQL等数据库也行只需要更改注解的属性;
1 | <dependency> |
0x02 源码解析并实现自己的JPA
讲解中自己实现Spring Data JPA 核心项目源码 GitHub - WellJay/jpa-source
最好配合视频,这块有点复杂,文章可能表述的不是很清晰;
原理简介
我们应该都知道我们定一个接口就可以直接使用仓储了,java中一定要有实现类才能调用。那么JPA是怎么做到的呢?其实能想到动态代理,那么我们就来自己实现一套逻辑包含 动态代理 + 动态注入代理类进入 Spring容器 中放便注入(MyBatis、Feign、JPA等很多框架都是这个核心逻辑,那么后面你也可以自己实现类似的开源框架了);
实战一下
核心原理入门
我们先debug一下任意一个查询,可以看到 JPA 是使用的 SimpleJpaRepository 这个类;
可以看到它把 JpaRepositoryImplementation 定义的接口都重写了一遍,并且核心都是通过调用 JPA 核心的 entityManager来实现增删改查,代码量太多只放出一个 save 方法看一个大概。
1 |
|
现在我们自己实现一个自己的 JPA 实现类;
1 | public class MyJpaRepo implements CrudRepository { |
有了实现类之后,我们肯定要配合动态代理覆盖对应的接口定义;并且通过简单调用一下,我们可以发现成功的调用了我们自己代理类并执行了查询方法;
1 | public class MyJdkDynamicProxy implements InvocationHandler { |
但是这样也太low了吧那么多接口定义,Spring Data JPA的实现方案肯定要动态扫描对应的repository目录并且动态的构造动态代理并且注入给Spring容器; 我们现在就来实现它;
完整的实现MyJPA
篇幅较长,直接略过现场讲解的一步步实现思路,直接实现最终方案;
Spring Data JPA 开启的注解是通过 @EnableJpaRepositories,虽然我们平时没有指定(SpringBoot帮我们做了autoConfiguration)。我们也像模像样来搞一个,专业点;
1 | ({ElementType.TYPE}) |
我们发现我们的注解定义了一个packages包名,你可以指定你 repository 的目录;核心的是 @Improt 导入了MyJPABeanDefinitionRegistrar 类;这个类实现了ImportBeanDefinitionRegistrar 它是Spring的一个扩展点;可以实现 bean 的动态注入;核心是16行;以及其中注入的 FactoryBean;
FactoryBean是一个工厂Bean,可以生成某一个类型Bean实例,它最大的一个作用是:可以让我们自定义Bean的创建过程。
1 | public class MyJPABeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar { |
核心的都写完了,我们来试一下,先写一个配置类,不会开启任何JPA相关的注解。我们也没用使用SpringBoot,仅仅开启了我们的自定义注解;(你可以在仓储包中加入任意的接口测试是否动态注入)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
(packages = "com.kok.jpasource.repo")
public class Config3 {
public void dataSourceConf(){xxx}
}
public class MyJPATest {
public static void main(String[] args) {
final AnnotationConfigApplicationContext ioc = new AnnotationConfigApplicationContext(Config3.class);
final TestRepository testRepository = ioc.getBean(TestRepository.class);
System.out.println(testRepository.findById(20L));
}
}
注意日志1
2---my customer repository---findById !!!说明调用了我们自己的仓储
Optional[User{id=20, name='asd'}]
最后我们debug一下任意 Repository 可以发现是我们自己得类了;
扩展思考?
时间和篇幅问题,把这个问题就留给大家。SpringDataJPA 提供很方便的 NamingQuery 如何实现的?我们只需要定一个方法名,他如何做到动态的查询条件,而非我们刚才实现的全部是封装自 entityManager 自带的查询;
userRepository.findByCode(name);
userRepository.findByName(name);
